Is DNA a Code?
 From the perspective of information science, DNA, specifically, the information carried by its arrangements1, is a code. It “is a system of rules to convert information — such as a letter, word, sound, image, or gesture — into another form or representation” (Wikipedia on Code). We know the rules2 and the conversions.
From the perspective of information science, DNA, specifically, the information carried by its arrangements1, is a code. It “is a system of rules to convert information — such as a letter, word, sound, image, or gesture — into another form or representation” (Wikipedia on Code). We know the rules2 and the conversions.
However, some people associate code or information to minds, to ideas, to meaning, to conscious control or design. In that case DNA cannot be a code; or one has to posit some kind of intelligence that predates life. Both extreme positions, both untenable.
The key insight is that meaningful recognition of input under some goal3 is not something exclusive to intelligence; learning algorithms do the same without understanding (see previous or previous). No matter how such a learning system works, it must have some kind of internal state and that must capture and encode information in some way.
Informational Entropy
To see that DNA carries in it a code, we can also take a more theoretical approach. Wherever we see things in some arrangement, we can calculate all possible arrangements and calculate how surprising the current arrangement is. This is called informational entropy. And using this we can state exactly what information is: the decrease of uncertainty at a reader4.
Things with very low entropy, cannot represent much information. Things with really high entropy are random and cannot directly represent any information; however, the information might have been compressed or encrypted. Anything in between has immediately recognizable structure and can be used to directly represent information. The lower the entropy, the less efficient the information was encoded. But high entropy also means algorithmically complex to decode and not very flexible. The entropy of human language is around 0.7, DNA around 0.9 (normalized entropy where 1 is maximum).
From here things do become much more interesting, human language can be represented using bits, characters, syllables, or words. Every scale will calculate a different entropy, so what scale to choose (pdf)? If you choose a good scale and use that to write language in, then you are writing close to maximum entropy. This is essentially what compression algorithms do.
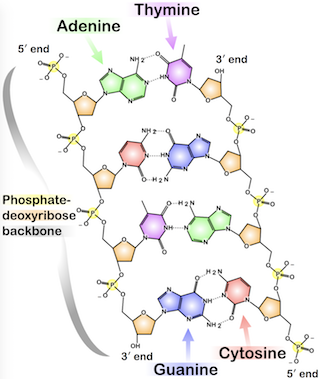
 Do note that entropy is not meaning. And for physical arrangements to carry information, there must be two levels of structure. The first level as the tokens or letters, for DNA these are the four nucleobases, represented with the letters ACGT. The second level is where we look for information. That is why patterns in sand dunes, or patterns in marble, are not comparable to DNA or a page from a book5.
Do note that entropy is not meaning. And for physical arrangements to carry information, there must be two levels of structure. The first level as the tokens or letters, for DNA these are the four nucleobases, represented with the letters ACGT. The second level is where we look for information. That is why patterns in sand dunes, or patterns in marble, are not comparable to DNA or a page from a book5.
Systems and Control
 But DNA is more than code. It is information that guides many processes in a cell. Similar to how computer programs control the CPU and output of a computer. Or how the punchcards6 on the Jacquard loom control the weaving pattern.
But DNA is more than code. It is information that guides many processes in a cell. Similar to how computer programs control the CPU and output of a computer. Or how the punchcards6 on the Jacquard loom control the weaving pattern.
Describing this qualitatively is easy. Create a model of the system at reasonable scales, find the parts that causally influence the rest of the system the most, look at the degrees of freedom and how big the physical changes are compared to how much it changes the behavior of the system.
For all three examples, punchcards, CPU instructions, or DNA, we see that the degrees of freedom are almost unlimited and hardly a change to the physical system at all. While the amount of useful sequences is much smaller and some of those can have profound effects on the behavior or output of the system.
Quantifying this exactly and providing proof is however very difficult. We can look at correlating time series, helped by how much informational entropy is transferred between systems. Or measure at various scales, places and over time and say something about causality and emergence (but see also this critique and this response to it). Or use automata theory and information theory to say something about complexity of organisms and their genotype and phenotype.
It does highlight one of my favorite topics. To understand complex systems, we must first use a reductionist approach to understand all the parts and interactions at various scales. But then zoom back out and construct causal models of the system as a whole.

-
So literally, DNA is a molecule, or more specifically, a gigantic family of molecules all chemically very similar, it is not a code. But it can carry information, and that information fits the definition of a code. So DNA, as found in our cells, carries a code, but isn’t a code itself. ↩
-
Because life accumulates information by a genetic algorithm, by constant self-replication, we can say something about what to expect. Namely that any mechanism that can copy information to the next generation will be utilized. So don’t expect life to use only “the rules”, but any other method as well; coloring far outside the lines, so to speak. All such other mechanisms we know of are called epigenetics. Also don’t expect to find some kind of clean if-then-else structures, instead expect messy networks of interactions. And expect a strange paradox of local optimizations but global inefficiencies. ↩
-
For life, (physical) entropy sets that goal. Namely, either have something tending to your existence, or yourself tend to it, or be in a constant state of decay and eventually disappear. Under the definition of a goal as a method for scoring outcomes. ↩
-
A conscious observer, a computer program, a molecular machine, a mechanical machine (also see). The reduction of uncertainty is a mathematical property, no mind or intelligence or meaning required. ↩
-
Entropy is a very compressed statistical measure, having medium entropy is an indication there might be an encoding, but perhaps we are looking at a random walk, or some Markov chain. Ideally we would like to be able to describe a third level structure that goes beyond a stochastic model, like grammar rules, start and stop codons, etc. ↩
-
Technically, just like how DNA is a molecule, punchcards were wood or paper. The punchcards carried the information that controlled the loom. ↩